HUE配置与各服务集成使用
HUE版本:3.12.0
Ambari:2.6.1.0
HDP:2.6.4.0
前言
Hue是一个用于开发和操作Hadoop的图形化界面。例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库,执行Oozie任务等。
该文主要对Hadoop服务的一些配置通过Ambari进行更改,同时也需要修改${HUE_HOME}/desktop/conf/hue.ini配置文件。
一、修改HUE时区
打开hue.ini配置文件,将 time_zone=America/Los_Angeles 修改为 time_zone=Asia/Shanghai
二、修改secret_key字段值:
打开hue.ini配置文件,修改secret_key值:
1 | # Set this to a random string, the longer the better. |
三、HUE配置WebHDFS
问题

解决办法
1. 修改hdfs服务的配置
1.1 etc/hadoop/conf/hdfs-site.xml(也可在页面上配置)
1 | <property> |
1.2 在ambari页面上,打开HDFS的”自定义core-site”,点击添加属性,输入
1 | hadoop.proxyuser.hue.hosts=* |
点击确定后,页面上就添加了这两个属性:

保存上述修改的配置,并重启HDFS服务,如图所示:

页面上的自定义core-site属性会自动添加到etc/hadoop/conf/core-site.xml文件
2. 修改hue.ini配置文件
2.1 修改fs_defaultfs和webhdfs_url
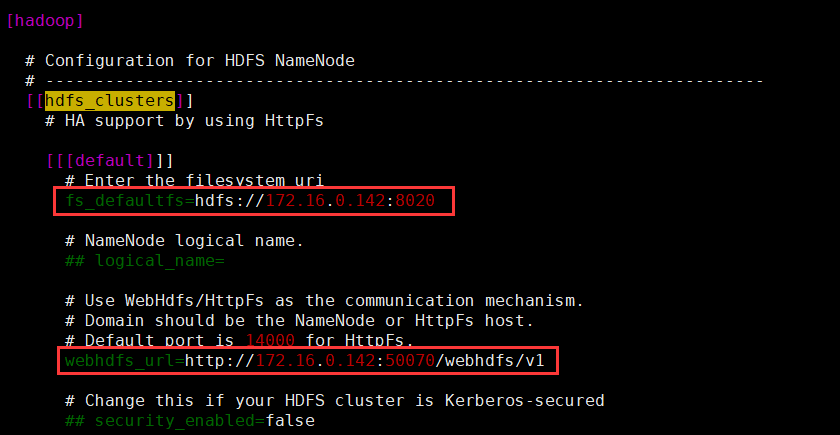
2.2 检查default_hdfs_superuser

确定default_hdfs_superuser=hdfs
重启HUE服务
四、HUE配置YARN
当HUE检查配置出现如下问题时:


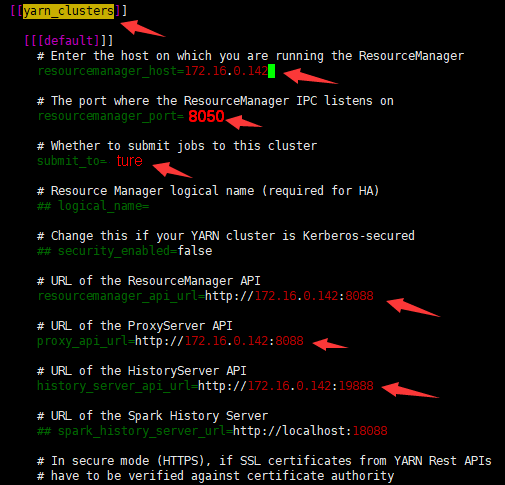
修改hue.ini文件,找到yarn_clusters选项,根据配置项的名称,主要确定组件所在主机及端口号,如下图所示:
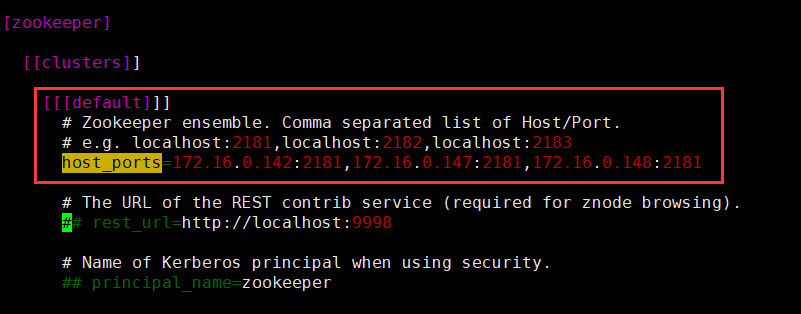
五、HUE配置ZOOKEEPER
只需要配置zookeeper的各主机节点+端口号即可。
六、HUE配置HBASE
问题集锦
【问题1】

【问题2】
Api 错误:TSocket read 0 bytes
解决方案
1. 安装HBase
安装HBase组件时注意,确保RegionServers和Phoenix查询服务有主机节点,并正常运行。

2. 添加自定义属性
进入HBase管理界面,配置选项中选择自定义core-site,添加属性,如图所示:

点击“添加属性”,填入:
1 | hbase.regionserver.thrift.http=true |

保存配置,并重启HBase服务。
3. 确保thrift服务正常运行
HUE读取HBASE的数据是使用的thrift的方式,默认HBASE的thrift服务没有开启,所以需要手动开启thrift服务。
thrift服务的默认端口为9090,在hbase master所在主机执行如下命令检查thrift是否被启动:
1 | netstat -ntlp | grep 9090 |
如果没有检测到9090端口,则需要手动启动该服务,在hbase master所在主机执行如下命令:
1 | 开启thrift服务 |

4. 修改hue.ini配置
如下图所示,根据箭头所指修改配置。9090为thrift服务的端口配置。
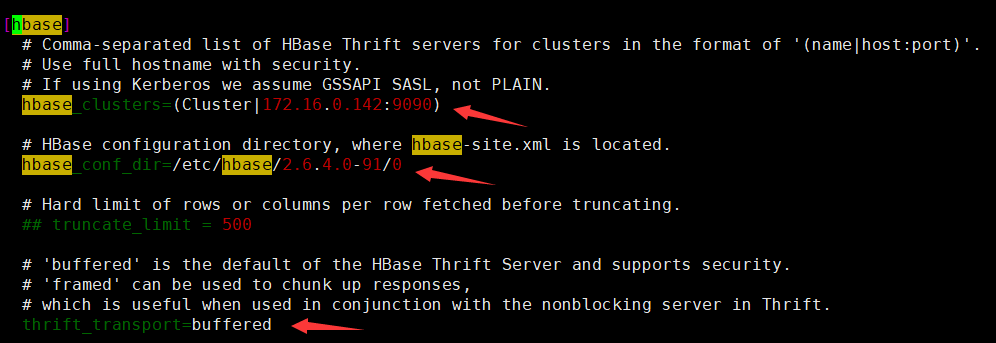
当配置HBase服务高可用时,hbase_clusters配置项的值为(Cluster1|172.16.0.142:9090),(Cluster2|172.16.0.147:9090),(Cluster3|172.16.0.148:9090)
5. 重启HBase与HUE服务
七、HUE配置HIVE
1. 修改hue.ini配置
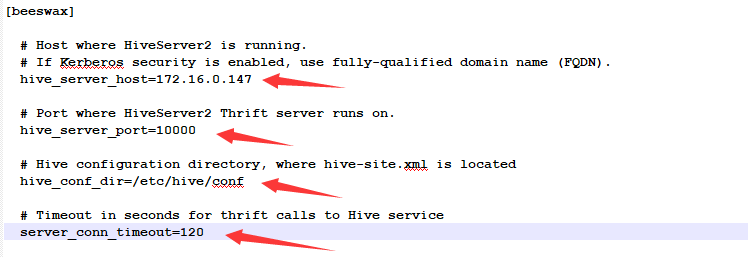
修改hue.ini文件的beeswax选项,配置如下图所示:
2. 修改HIVE服务配置
问题集锦

解决方案
2.1 Allow all partitions to be Dynamic
进入hive管理界面:配置选项中点击General,将“Allow all partitions to be Dynamic”的值由“strict”改为“nonstrict”,如图所示:

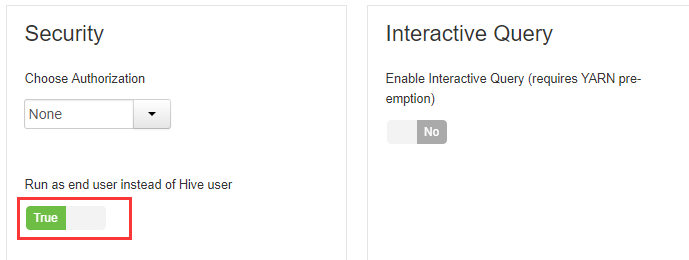
2.2 Run as end user instead of Hive user
将true改为false,重启hive。
默认情况下,HiveServer2以提交查询的用户执行查询(true),如果hive.server2.enable.doAs设置为false,查询将以运行hiveserver2进程的用户运行。如图所示:
八、HUE配置OOZIE
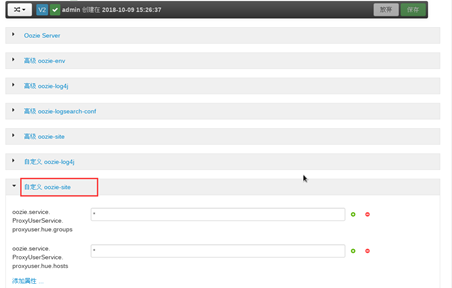
1. 配置oozie的hue代理
通过ambari,打开oozie配置面板,选择自定义oozie-site,如图所示:
添加如下配置:
1 | oozie.service.ProxyUserService.proxyuser.hue.hosts=* |
2. 修改oozie时区
将oozie时区改为东八区
在自定义oozie-site内,添加:
1 | oozie.processing.timezone=GMT+0800 |
保存oozie配置修改后,重启oozie服务。
问题
failed to get oozie status
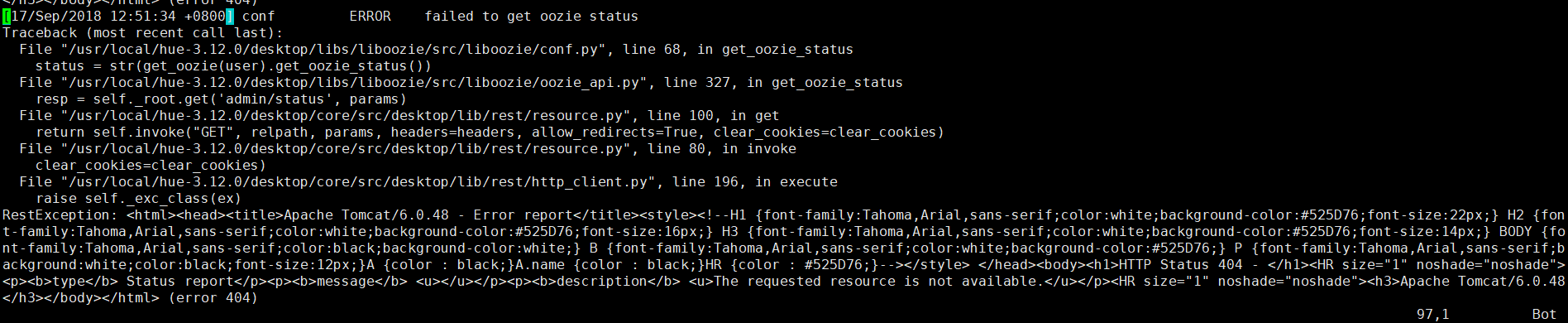
解决办法
修改oozie url链接的值即可,oozie所在的主机+端口号。

记得重启HUE服务。
九、HUE配置SPARK
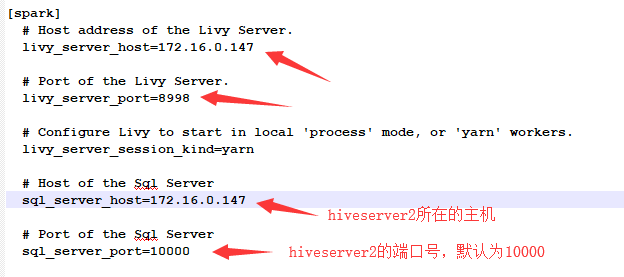
1. 修改hue.ini配置文件
hue配置Spark需要安装spark livy server组件,默认端口为8998;spark sql的配置依赖于hive,配置如图所示:
还需要配置Spark job history server配置项,该配置项在[[yarn_clusters]]内。
1 | spark_history_server_url=http://172.16.0.147:18080 |
保存配置修改,重启HUE服务。
2. 修改Spark服务配置
通过ambari,进入spark管理界面;配置选项中选择高级livy-conf,将“livy.impersonation.enabled”的值修改为false;将“livy.server.csrf_protection.enabled”的值修改为false。如下图所示:
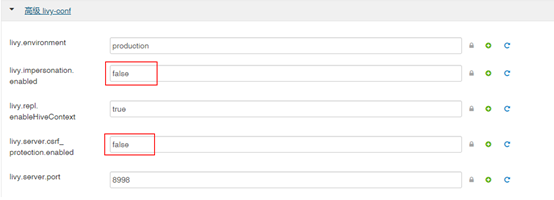
保存配置修改,重启Spark服务。
十、HUE配置NOTEBOOK
按照下图所示,配置NOTEBOOK。

其中NOTEBOOK支持很多种语言,假如需要删除掉一种语言,那么可以将该语言注释掉,比如删除impala,如图所示:
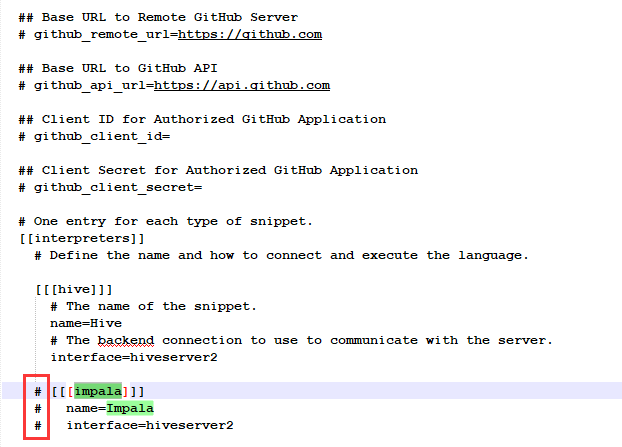
重启HUE。
我们可以使用NOTEBOOK内支持的Spark SQL、scala、pySpark来操作使用Spark。
十一、HUE配置Mysql数据库
HUE服务默认使用的是Sqlite数据库,但是该数据库当数据量大的时候,容易出现卡死状态,所以现在我们将用户名密码等一些HUE配置数据迁移到Mysql数据库内,具体做法如下:
1. 配置mysql
1 | show databases; |
2. 配置hue.ini文件
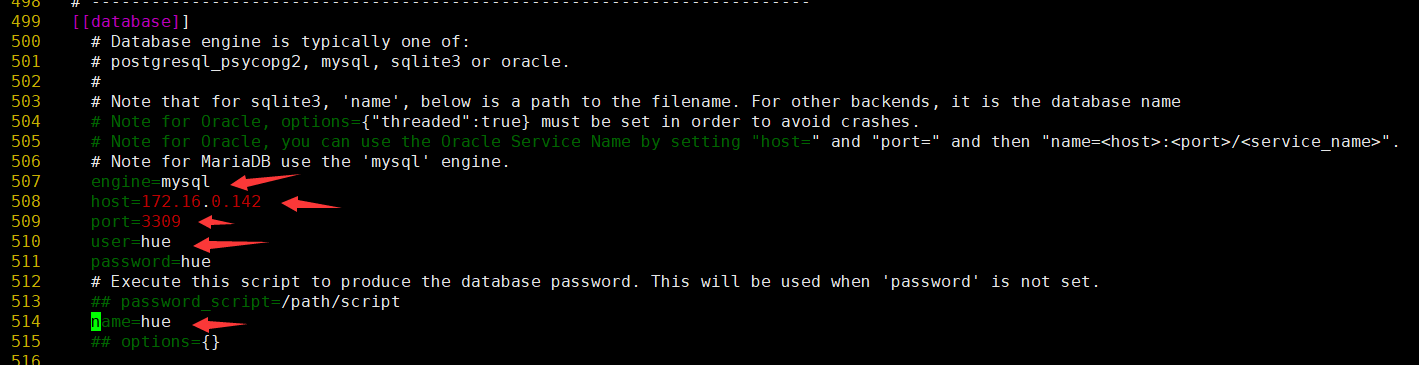
3. 初始化数据库
3.1 切换到hue安装目录
3.2 数据同步
1 | bin/hue syncdb --noinput |
3.3 启动HUE服务
启动HUE服务,访问ip+8888,用户名和密码首次需要注册。
十二、HUE配置RDMS
HUE可以配置RDMS,在HUE页面上,可以对RDMS数据库进行一些sql操作。支持mysql、oralce、postgresql数据库。当前仅介绍sqlite与mysql数据库的配置,如下图所示:
1. 配置sqlite数据库
如果想在hue页面上对sqlite数据库进行sql操作,需要进行如下配置,其中sqlite name配置项为hue安装目录下的desktop.db文件的路径。
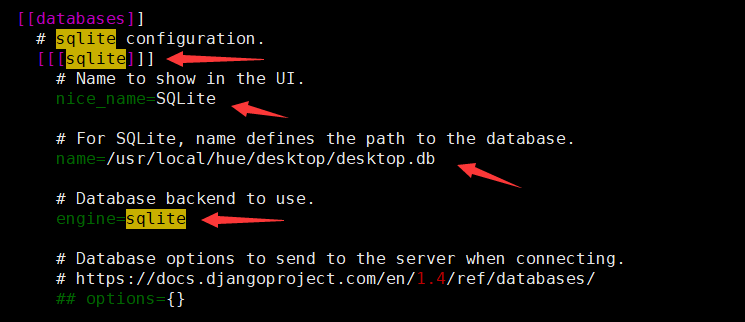
2. 配置mysql数据库
如果想在hue页面上对mysql数据库进行sql操作,需要进行如下配置,其中上图的mysql name配置项可不写。不写就代表读取mysql所有的数据库。

十三、总结
本文主要讲解了HUE如何与Hadoop生态系统的一些组件进行集成使用,主要是修改的各服务的配置文件及HUE服务的hue.ini配置文件。
本文内容支持HUE与HDFS、YARN、HIVE、HBASE、RDMS、OOZIE、SPARK、NOTEBOOK等服务集成使用。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !



原文作者: create17
原文链接: https://841809077.github.io/2018/09/17/HUE/config hue.html
版权声明: 转载请注明出处(码字不易,请保留作者署名及链接,谢谢配合!)

